1. A brief summary of git#
1.1. The what and why of git#
Git is a distributed version control system. It can encourage reproducible science by, among other things:
Tracking the history of your projects, allowing you to reference specific snapshots.
Allowing you to easily revert mistakes or to jump back in time.
Providing a free “backup” of your code on a remote server.
Enabling collaboration on projects and coordination of tasks via branching and merging (=> what this workshop will focus on).
Automating things like unit tests and deployment.
You will commonly interact with three distinct areas where files can reside in git: the working directory, the staging area or index and the repository consisting of commits or snapshots. The working directory is just that, the state of the files as you see them on your machine when you open them in a file editor (WYSIWYG!). The repository is where snapshots (or commits) of previous states of your working directory live. The staging area is for composing the shot and it allows you to review snapshots before saving them and also to only snapshot specific files or even parts of files.
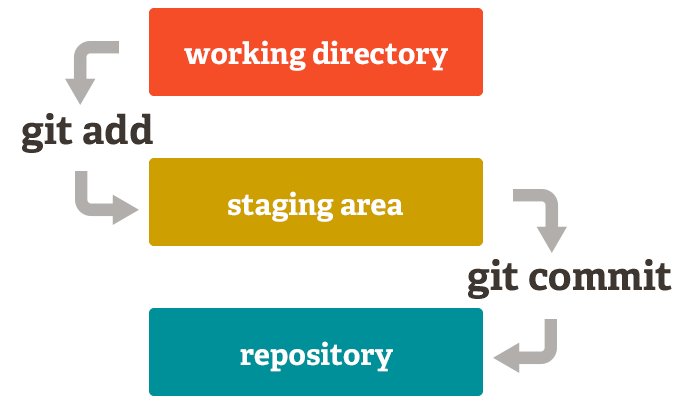
The three stages of git#
See also
As always, the Pro Git book contains a nice description of the what and why of git too: https://git-scm.com/book/en/v2/Getting-Started-What-is-Git%3F.
1.2. A peek under the hood#
Warning
Below is a very brief summary of what is explained in the git gud presentation on git’s internals (this link points directly to an overview page with other resources, press ESC to show entire presentation).
Depending on your familiarity with git, some of this information might still be too hard to digest right now. If so, come back to it later after you have completed the rest of the workshop. Or click on the sources of the figures to learn more.
Under the hood, git is all about those commits.
More specifically, it consists of a directed acyclic graph that connects commits (snapshots), pointing to trees (directories), pointing to (file) blobs. Blobs represent files and their content (at a particular point in time), uniquely named via a hash function (SHA-1). Trees represent directory structure and file names. Commits record meta-data about the snapshots (who created it? when? what is in there?) and their names are also derived from a hash function of their contents.
Note
This results in commit IDs always being unique, being based not only on the state of your files, but also on when it was created and by whom. This will become important when we talk about certain types of conflicts later on.
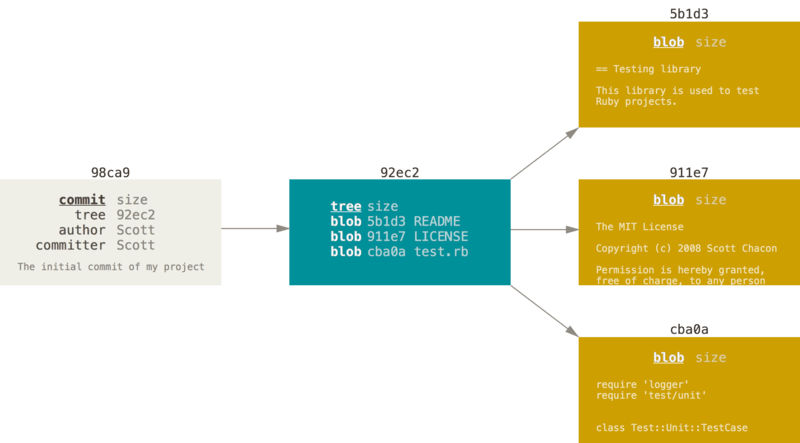
Overview of the different git objects: A commit object, shown in grey, describing the author and date. It points to a tree object, which lists the contents of a directory. Each filename line points to a specific blob object. The blobs store the actual content of the files in the repo. All git objects are described by a SHA-1 hash (shorted to the first 5 characters here). Source: https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell#
The succession of commits pointing to previous commits forms a history of snapshots of a repository at specific points in time. The history isn’t always a straight line, because a commit could very well have multiple parent commits, e.g. when two different commits are merged into a single one (more on merging later).
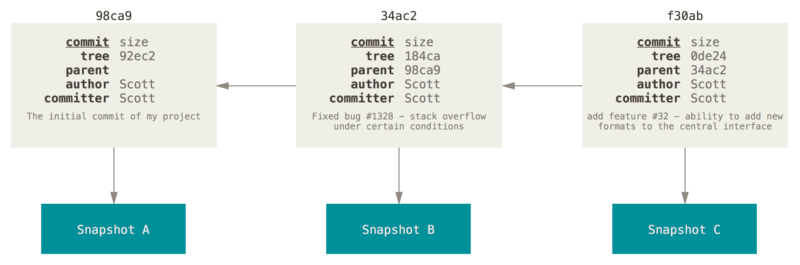
History of commits: Commits point to one another and form a history of snapshots. Source: https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell#
Lastly, take note that in this view, branches are nothing more than pointers/labels/bookmarks that refer to specific commits. The HEAD is yet another pointer, that keeps track of which branch (or sometimes a specific detached commit) your repository is checked out at (usually, see detached HEAD). It is used as a reference and it tells git which files to show you in your working directory when switching branches or when checking out older commits). This is also how git is able to tell which files were altered in the working directory compared to the previous commit (or when performing a git diff).
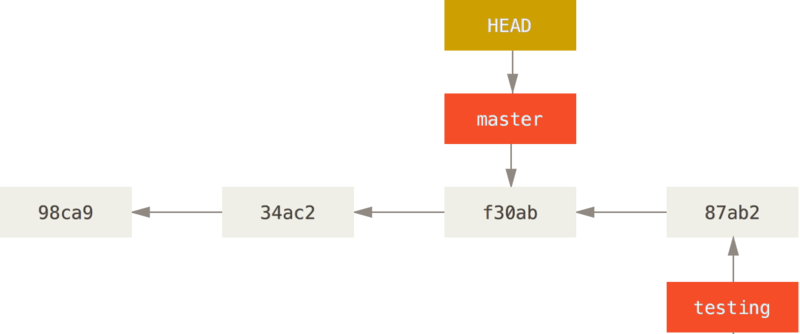
Branches as labels: in this example, the repository is checkout out at commit f30ab, currently also known as master (as indicated by HEAD). There is one newer commit based on this one (87ab2), bearing the branch name testing.
Source: https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell#
Remote repositories are another aspect worth talking about, but we will do this in a later chapter.
This brief overview covers most of the important things to know about git. You can refer back to it later after doing some exercises, at which points things will hopefully start to make more sense.